This week we begin preparing for our final project for Facts & Fictions. I’m taking this opportunity to apply my newfound skills to my current project by visualising the entries from January over the period of 2005 to 2015 (January x 10). The amount of data over this period is a good size to work with for the final project (which will culminate in a group show in another 14 days), and I think it is a perfect chance for me to try visualising a part of my FYP.
These are some of my process shots:
Filtering entries from January 2005: there are 17 items, of which I am going to individually tag and categorise them. In 2005, I was still on Blogger, and the blogging platform is very simple, and I don’t remember tags or categories existing on Blogger then. So it was quite a good thing that my entries are left un-tagged/categorised, now I can be very specific about how I want to label the entries for the sake of this project.
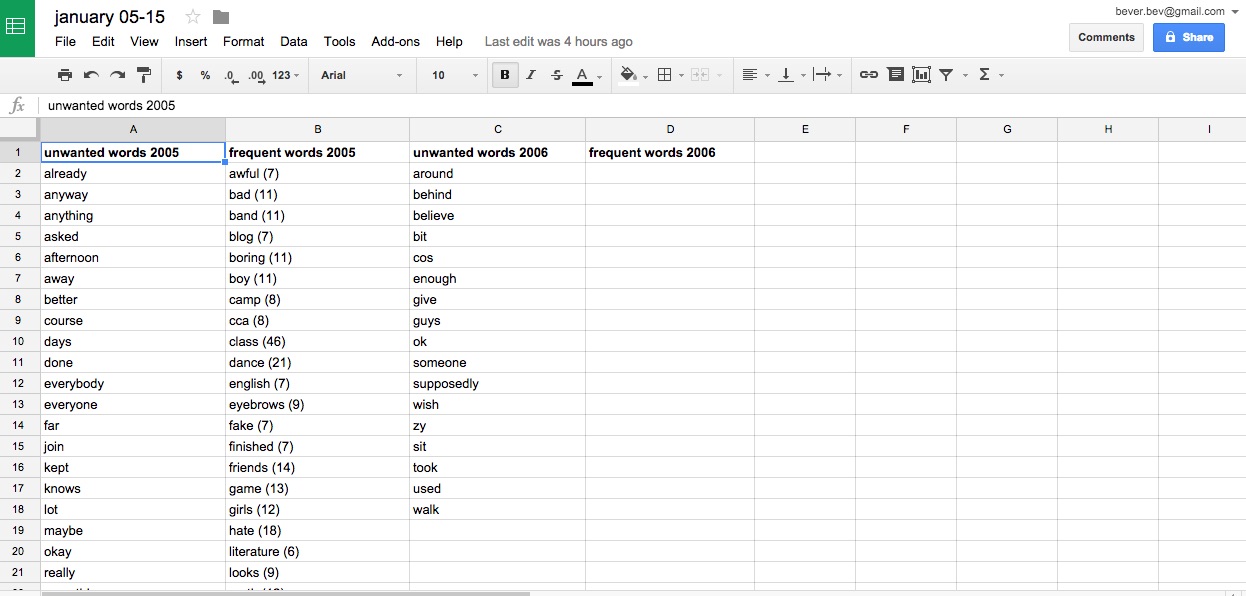
I am also doing tagcrowding again, with the help of Miriam Quick, who does research for information design. With her guidance, I learned how to use Tagcrowd in a more resourceful manner. She also taught me how I can use Google Sheets to my advantage, by showing me lots of cool stuff that can be done with Sheets. After running through my text in Tagcrowd, I went on to omit common words, and made a list of frequent words I use. This is different from individually tagging my entries, which I feel is something I would have to do manually if I really wanted to be specific about the topics that I wrote about, and I think there’s no shortcut to this part. Tagcrowding would be useful for highlighting linguistic details like: lingo, swearing, emotive words, and even names. This could be an interesting area to visualise on its own, so at the same time, I am also creating an additional dataset for that aspect.


I’ve installed WordPress on my own site again, for this January project. Currently, there’s nothing fancy there yet, but I think the taxonomy is taking shape and I am very excited about it. I’ve just finished importing entries from January 2005. You can take a look at it as I update it with more January entries, although I must warn you that some of the entries are very juvenile. Please bear with my 13 year old self. Haha.
Overall, this whole process of creating the metadata is far less agonising that I expected it to be. Before embarking on the January project, I read through all the January entries in the ten years, which left me in a very sombre and nostalgic mood, but all of that is gone when I go all technical about the work. That really gave me an idea to write a reflection piece after I have completed making these datasets for my archive. It would be interesting to include in my process book.
I’ll share more when I finish making the datasets for each year, and also my process on how I will visualise everything.