For this assignment, we were given a patch and told to tweak it by adding extra functions / effects to it.
So here are the two things I did:
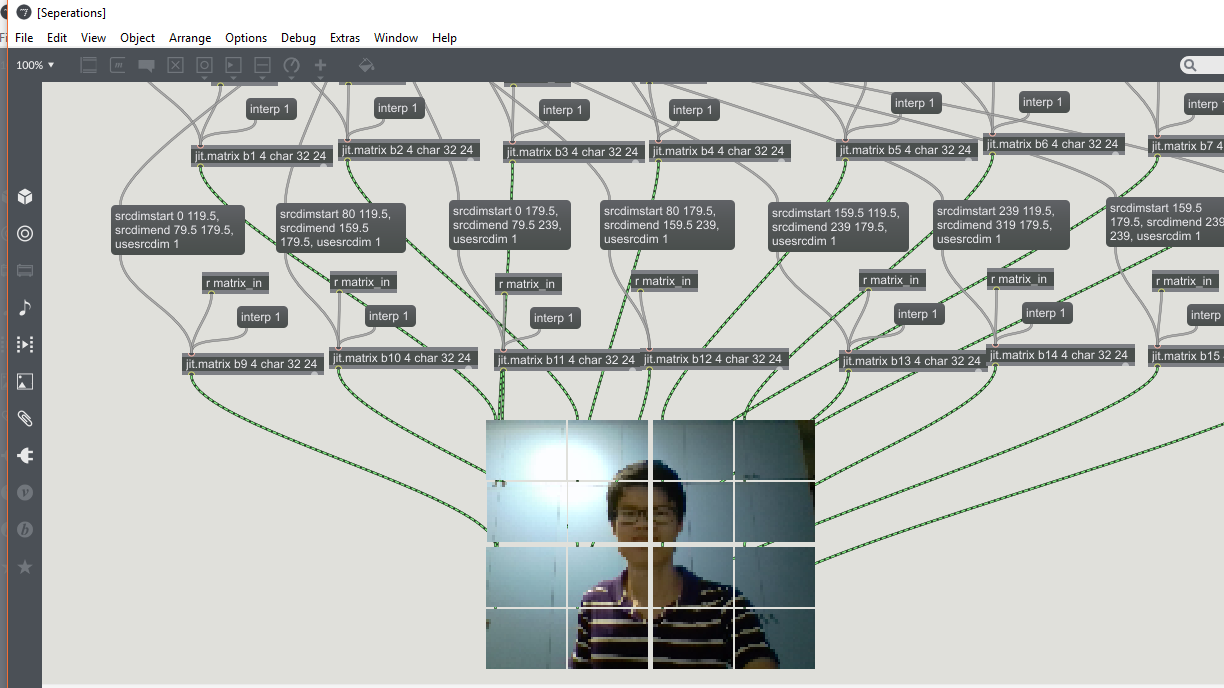
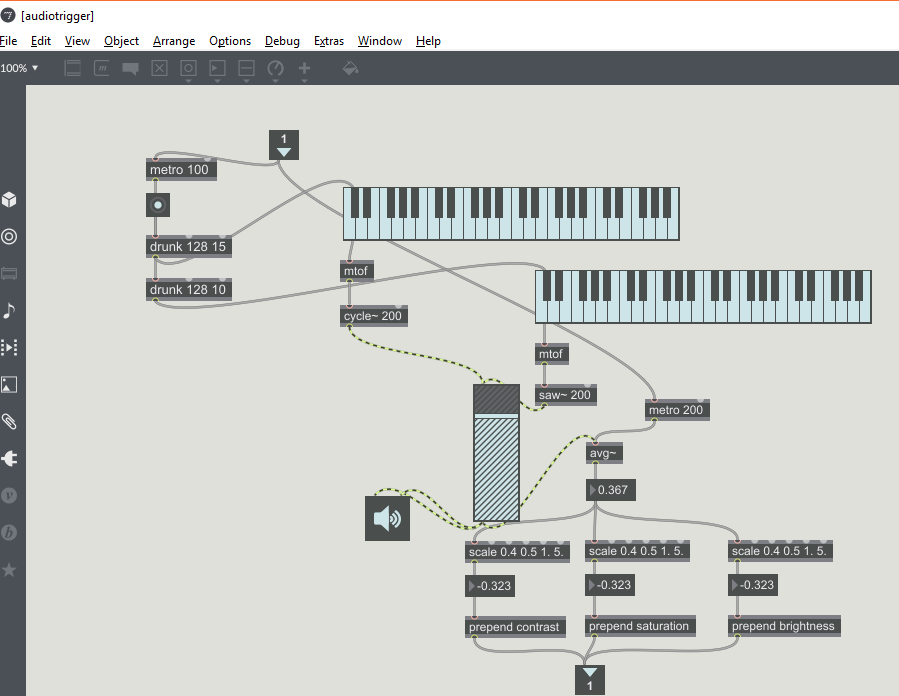
Increased the definition from originally 4 crop pieces to 16.
Add an audio played with a drunk object in step and get those average signals to prepend to the brightness, contrast and saturation of the final image
So I ended up having what I felt was quite a cool colourization with a matching soundscape to it. The figure also looks more define and seen clearer as I gesture or move around the screen.
So this wraps up the last class assignment. I learnt quite a bit for Max this semester. Hopefully it might be useful in some ways in the future. Although I greatly still prefer coding in Java or C# for Unity. But I guess having the ability to control and manipulate in real time has its added advantages (provided computer can process those effects). Yup, so looking forward to what the next semester brings!
Winzaw and I looked at some tutorials found on youtube and tried to mash some of them together.
So the patch records voice for 8 seconds and playback in a robotic tune for twice over. and this audio playback will affect the particles to generate some visual feedback. Afterwhich the process happens again automatically. had to create a randomizer to randomize the voice playback so that it will alter the voice dynamically.
This is to see what we can do with particles and the audio feedback and how to combine. We will see how this can be applied to our ideas for the project
Our project will be split into two separate endeavors which eventually be combined into a seamless interactive experience. We are interested in the distortion of sound and images that respond to each other in a cohesive manner. This video is an example to illustrate.
Aims:
Sound. We want to have the patch constantly recording and playingback things people say to it. So this will probably be the basis for interaction. No buttons or sliders, just purely saying stuff to the patch.
Visual. Based on the pitch, frequency of the sounds playingback, we will get the jitter to generate visuals, either in the form of particle systems or in the form of real-time distortion of the images captured via webcam.
Timeline:
28th Mar. Working patch for sound recorder and playback (with/without distortion)
4th Apr. Working patch for visuals (i) in terms of particle systems responding to the sound recorded or (ii) in terms of distortion of the webcam grabbed image (if that is possible)
11 Apr. Connected patch for the two endeavors and fine-tuning the timing and sequencing for interaction
For this third assignment, we are using MAX and MSP to create a Selfie Instructor. And just to note, I did not add any music or additional voice overlays in the video, so what you hear is only the tracks invoked by MSP as well as my own reactions.
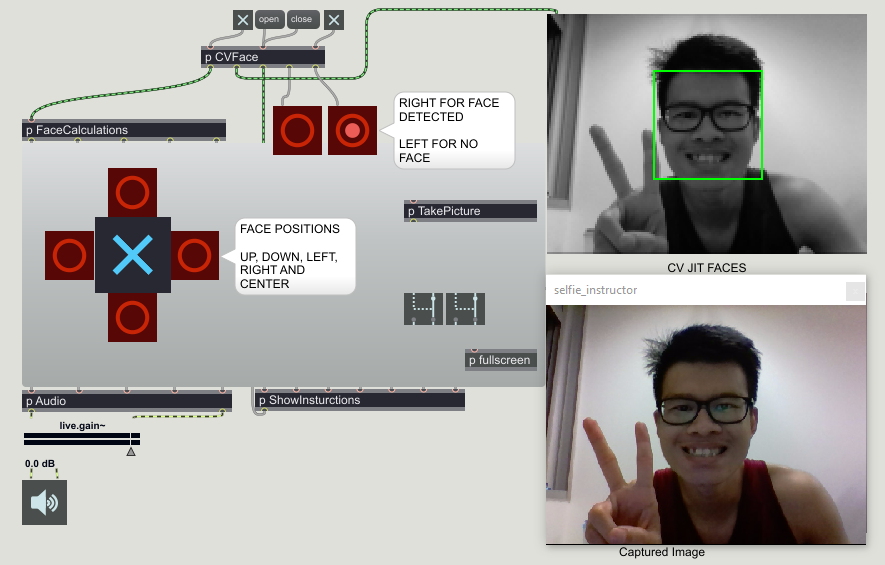
It basically detects where your face is on the screen and gives you instructions. So end result is to get you facing forward looking at the camera with your face in the center before it says “OKAY” and allow you to take the picture! Which you can take simply by making a sound. KA-Cha!
Sensing.
Coordinate info from cvjit.faces matrix used to calculate the position of face with respect to the screen
cvjit.faces coordinate info is then used to determine if the face is in the LEFT, RIGHT, UP, DOWN quadrant of the screen, or if there are no faces at all
MSP can detect if sounds are made through the Microphone
Effecting.
Relative position of the face (LEFT, RIGHT, UP, DOWN quadrant) from Sensing is then used to:
Invoke audio playback of respective tracks on a playlist in MSP
Display instructions on the screen corresponding to the audio playback
So basically telling the user to go in the directions towards center of screen depending on which quadrant the face is in and to also alert them that the app is running and to look at the screen should they be looking away
When user is in the centralized position, the screen will display “OKAY”, and the MSP sound detection through Microphone mentioned earlier on will be activated. User can then tap or say something at the screen to have their photo taken.
It was great fun doing this project and I kind of wanted to have a bit of humor as you can see, because I like the idea of machines scolding people and making them do stuff. Also it was good to finally be able to attempt combining MAX and MSP together in the same patcher. Having a proper layout was also essential in helping the process along so that I could have great visualization of the dataflow.
Of course, there are still some issues. Like displaying the images there will be this glitchy effect because the bangs are being outputted at a steady rate when user goes into any of the quadrants. Although in this case it kind of worked to the assignment’s advantage as it creates a sense of urgency to follow the instructions the user is being yelled at.
However would be good to know if there are elegant methods of controlling these flows. I know that the onebang can be used as a stopper valve for this and I actually used that for the center quadrant. However for the side quadrants you tend to not want too long a delay for the onebang or else it does not reset itself quick enough to react to the next position the user gets into. Whereas for the center it is fine because they will stay still to have their picture taken. So that is kind of the reflection on this assignment and I hope to learn more subsequently!
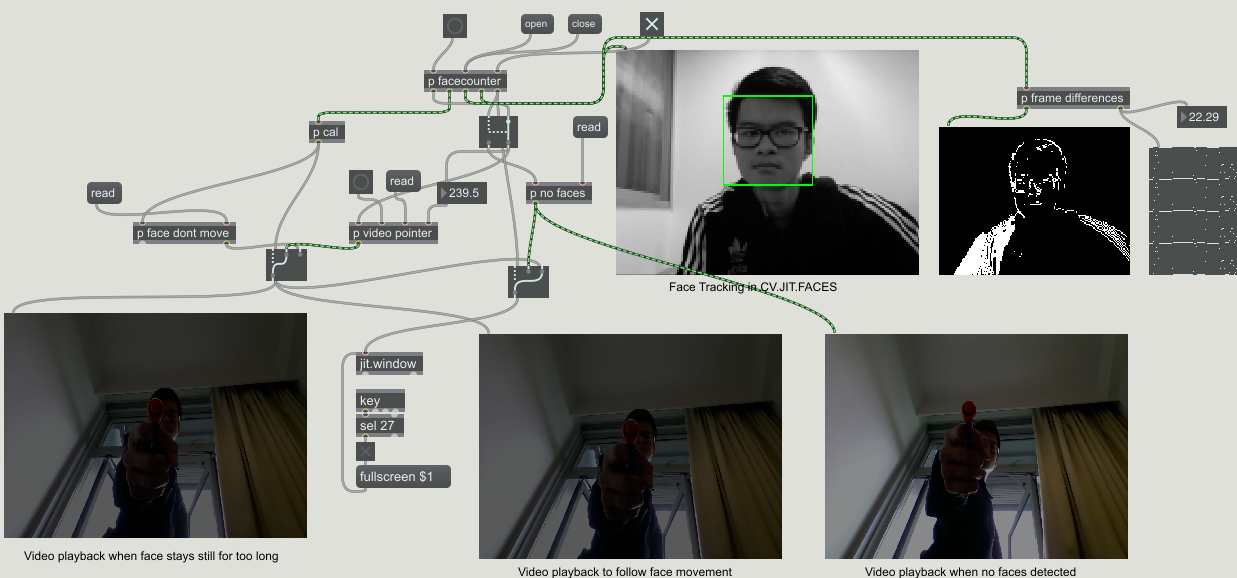
Hey! So this second assignment I am calling Gun in Your Face!
So to sum up the assignment first:
Sensing.
Coordinate info from cvjit.faces matrix used to calculate the position of face laterally across the screen
cvjit.faces detects when the face is at a certain proximity from the screen
cvjit.faces also detects when the face is off-screen or there is no more faces
Effecting.
Value for face position used to determine which frame from the video of gun moving left and right will play
When face is close to screen, playback of the gun firing video is triggered
When no faces are detected, video of me spinning the gun is set on loop like a ‘screen saver’
All videos have a 1.5seconds crossfading transition
I am rather satisfied with the outcome and more in-depth presentation of the process is in the video below. Here I really wish to express that apart from learning the stuff in MAX, what was really important to me was the asset creation in the assignment. What I have attempted was to use the assets to my advantage, the angle of the shot, the composition of the videos, thinking about transitions. And I really spent quite a bit of time dwelling on those aspects. So this played out really well as for most of the time in interacting with this piece, the transitions are as smooth as I would have them.
Also, this time I attempted to organize things a little more, showing only the essential stuff and visual information in the main patcher while the complex computations are put into the hidden ones.
What could be improved for this assignment is maybe thinking of ways to track vertically as well.
Quite Satisfied with this first try at Max, would like learn more! So what I have achieved:
Sensing.
cvjit.faces detects when one at least one face appears on screen
Face size is calculated by the coordinates of the approximated perimeter given by cvjit.faces
cvjit.faces detects when the face is off-screen or there is no more faces
Effecting.
Mirror is inverted to the correct orientation
Opacity is triggered based on proximity
Screen will fade to black when no face is detected
The reason for the cutting to black when no faces are detected was because I wanted to eliminate the issue of screen flashing whenever the face is out of position as cv.jit.faces requires the user’s face to be very frontal else it will not register.
However I would also like to explore how to limit to only working when there is ONLY ONE face… that will be more trail and errors, will get to that sometime later.
Below is a video log for my own documentation of process, so I can review the thinking process behind the max patcher for this magic mirror assignment.