The semester has passed by so quickly and what started of as an ambitious idea while I was brushing my teeth (it’s true!) has materialised into a WordPress.com site, with three amateur visualisations that I am nevertheless extremely proud of.
As my site grew bit by bit, I feel that I have grown with it, both in terms of skills and critical analysis of the data I was handling. And so I pen some of my thoughts in this post.
Ideas and goals
My initial idea for the project, Virtual Thumbprints, was intended to turn my own Facebook data into an abstract collage of network diagrams. I got really excited and started producing some visualisations on Gephi.

Network graph of friendships in the OSS NTU Facebook group
While comments from the class were positive, it just felt like there was something lacking in the idea. First, it felt too safe. I have taken a Network Perspectives class and am quite familiar with Gephi, so producing the visualisations would have just taken about 10 minutes each. Second, it didn’t seem like something that had external validity, meaning that it could be generalised to a greater context, and would be thought-provoking for people all over the world.
So I started thinking of other ideas, and coming across Manovich’s Phototrails proved to be the turning point. I read their project documentation and realised that they had developed a macro for ImageJ, a software I had never heard of before. Perfect!
Concept and technical realisation
I began envisioning what I could produced with ImageJ, and my long-held scepticism towards politicians’ Facebook pages somehow came in into the picture. As a Singaporean of Indian descent greatly influenced by American culture, it didn’t take me long to settle on studying PM Lee, PM Modi and President Obama, all of whom are active on Facebook.

Two of the politicians I decided to study just met for the first time yesterday!
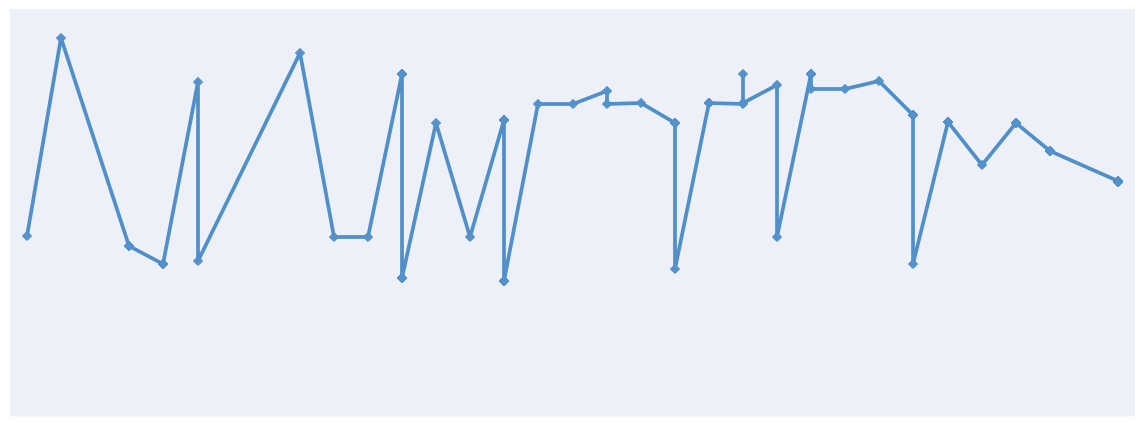
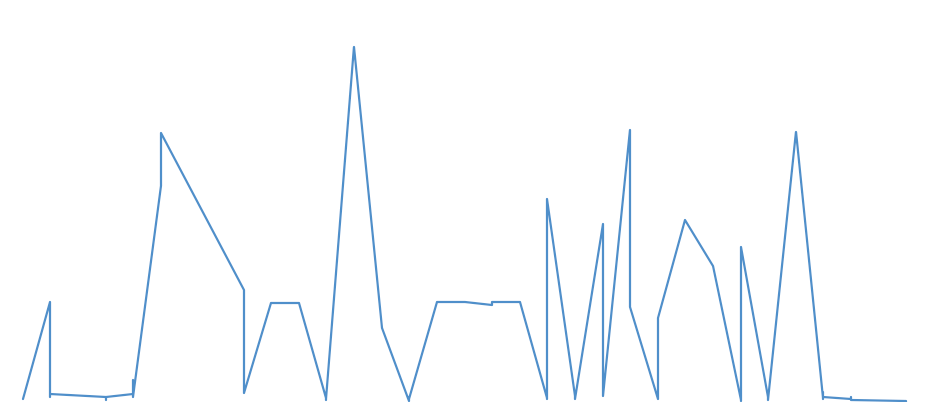
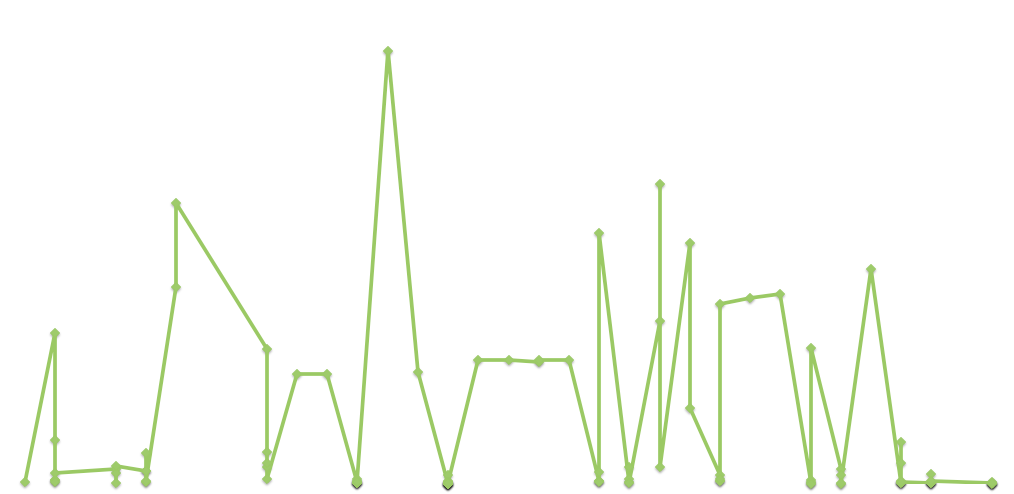
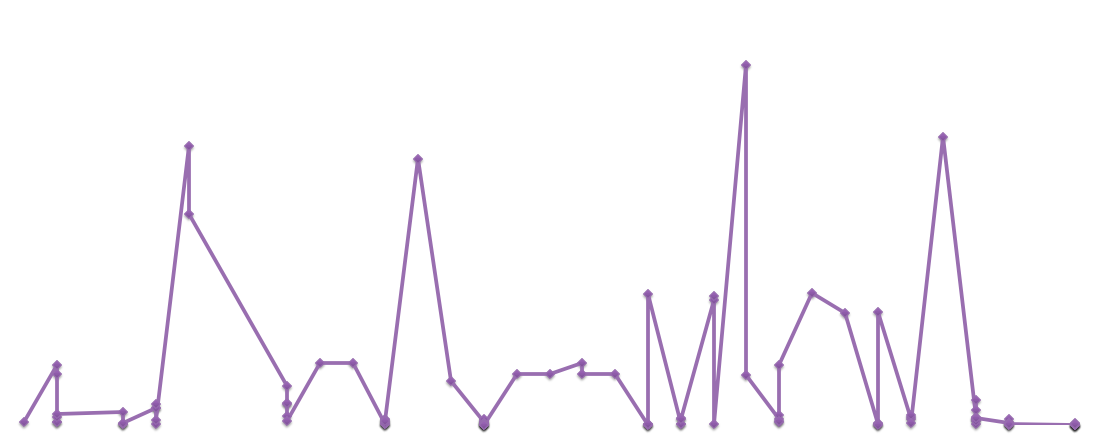
As I started collecting my data, with the help of Juan, I did some preliminary analysis of the information I had, producing all sorts of interesting graphs. It occurred to me that I didn’t have to be restricted to ImageJ, for Excel, while commonly associated with dull administrative work, provides scope for creativity as well.
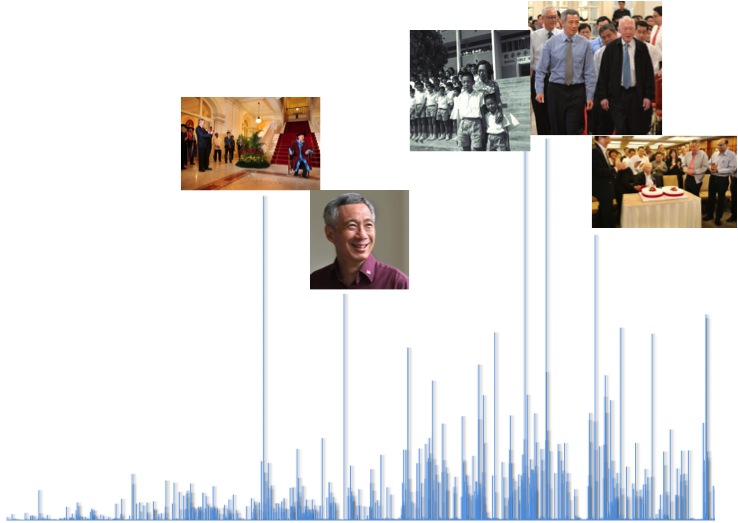
Graph of PM Lee’s Facebook likes per photo over time. The top three photos feature his father, former Prime Minister Lee Kuan Yew
While Excel is an excellent tool for critical analysis, feedback from the class also helped me realised that it is not dynamic enough, and also not best suited to the online medium. After all, net art is indeed about audience engagement and interactivity.
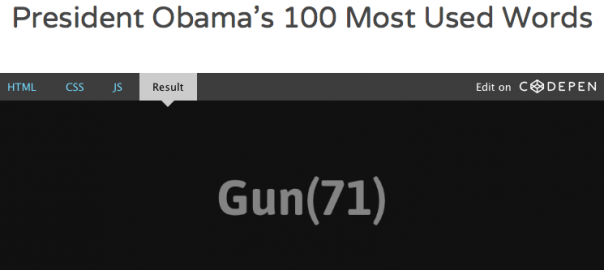
I was lost for a while and then remembered the open-source sharing platform Codepen we used in the Facebook network micro-project, where I can fork others’ pens to visualise my own data. So I produced a simple pen to replace my complicated word cloud. Not very impressive work, but I think it’s a great step for me because I was quite intimidated by code at first.
And along this process, my initial vision of using ImageJ has not faded away. I have been, and am still collecting data for ImageJ (I have 2700+ more jpeg files to download, rename and input the names into Excel), and hope to realise these visualisations soon.
Bridging my practice
Virtual Politics is based on the journalistic values of being faithful to information and presenting it with maximal accuracy. Settling on this principle was not an easy decision to make, but the process of consultations and documentation on this site helped me distill my thoughts on the issue.
At first, I wanted to break out of the mindset of a journalism student, but after some time, realised that what I truly wanted was to uphold transparency and accuracy. I wanted my work to stand up to scrutiny should someone important ever come across it, hence the more scientific approach to an art module. And I began to appreciate that art and science are not mutually exclusive, and that data visualisation on the Internet is a unique artistic approach to a traditionally scientific method of analysis.
Overall, I am really glad to have had the opportunity to immerse in data mining and visualisation, an invaluable skill to have in this information age. Surveillance through data visualisation is both fascinating and scary. As Manovich put it:
We seem to be back in the darkest years of Cold War, except that now we are being tracked with RFID chips, computer vision surveillance systems, data mining and other new technologies of the twenty first century.
-Manovich in What comes after remix? (2007)
I guess my message to Manovich would be that perhaps not all hope is lost. Because with open source software, the table can be turned, and the man-on-the-street may now have the ability to monitor the powers-that-be.


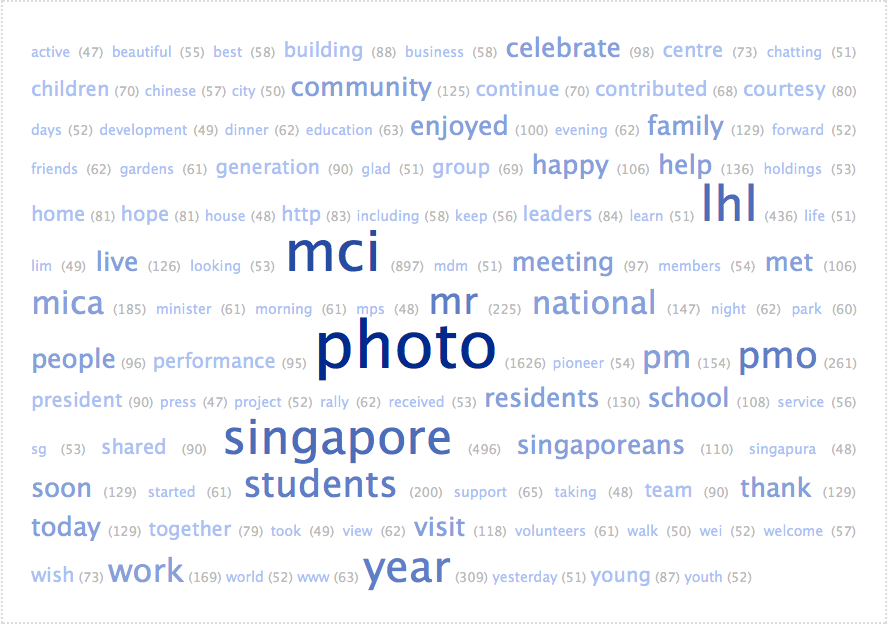




 Pie chart showing the different countries at which the 100 photos were taken.
Pie chart showing the different countries at which the 100 photos were taken.


























