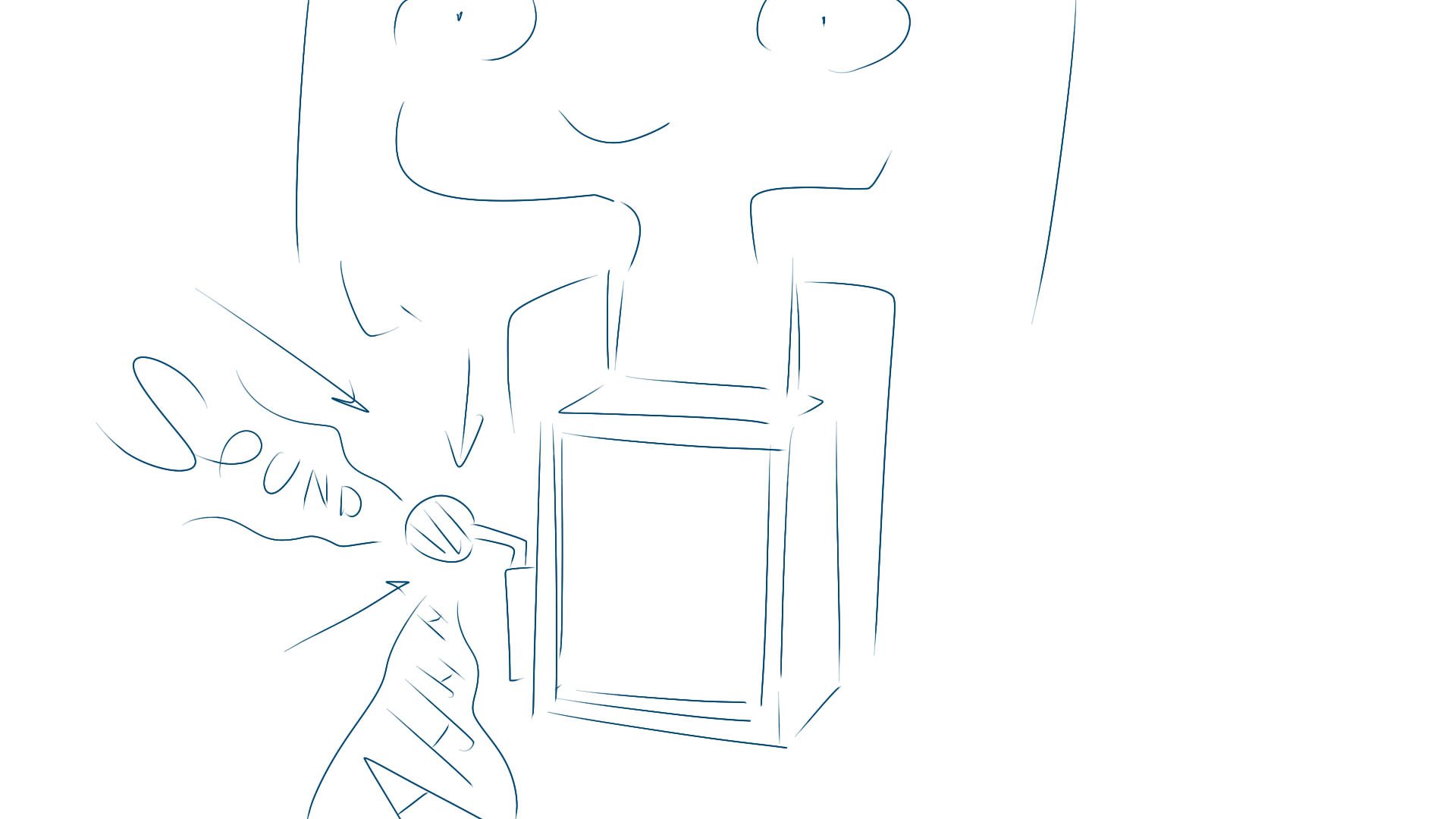
Elizabeth and I tried making a better prototype based on the comments of the first body-storming session.
PROTOTYPE II
It’s an accessory on the forearm now. Glove? Watch? Eitherway, it needs space to store all the components.
In particular, we tackled the issues of:
It seems to made to be extremely annoying
We determined that sound output was unnecessary and thus removed it, leaving the only possibly annoying thing as a set of flashing lights
The message of “interstices between sound as singular versus as a whole” did not come across clearly as it was too abstract
We concluded that as long as the participants have some sense of “all the sounds I’m hearing are represented together through these lights I’m seeing”, the message has been adequately received
The hat form is effective for engaging others, but not much the participant (who can’t see the output)
We changed the positioning to the forearm, such that both the participant and others are able to engage with the accessory effectively
The accessory is difficult to approach, and appears to be an individual-based experience
We altered the form from one magnificent accessory to multiple petite accessories, such that it looks more approachable and can be worn together than alone
Instead of code which analyses the sound and activates the lights accordingly, this prototype uses my brain.
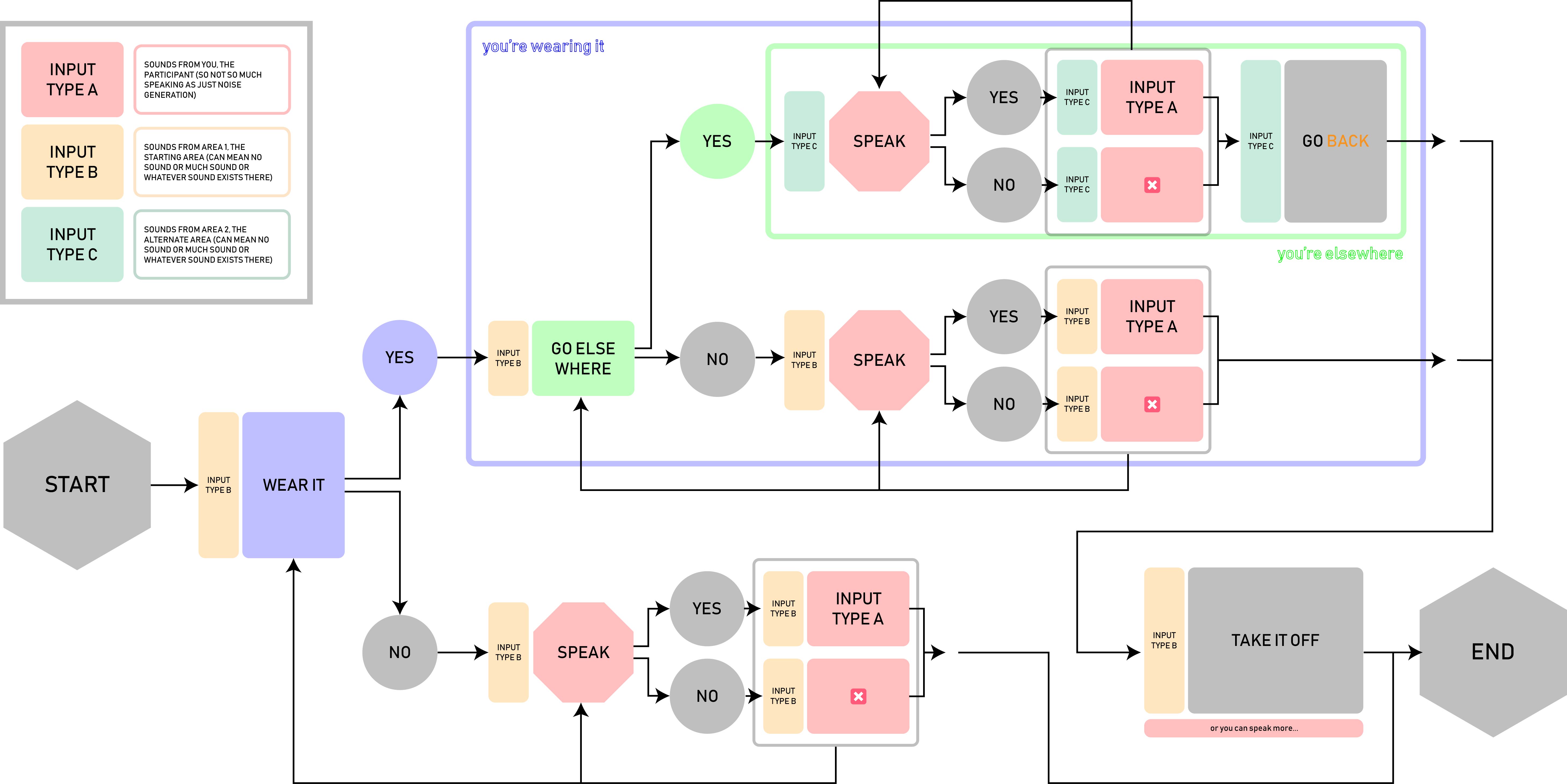
FLOWCHART
Note that Environmental Input, i.e. Type-B and Type-C, is a variable which can take on any value from no sound to extreme sound. Input Type-A, on the other hand, is differentiated here as either “existing” or “not”.
A flowchart is rather awkward for our project as our accessory creates outputs with or without your input (i.e. with environmental input), and your input can be involuntary (i.e. inevitable sound creation). Thus, we’ve created a flowchart with what is an intended sequence of actions, though the SPEAK action is always available, and INPUT TYPE B/C is always present.
LOGISTICS
We will likely aim to make as many as the amount of microcontroller boards we can procure (currently, 2 owned personally, 2 loaned from school).
Items required:
Power: Battery*, Holder/Adapter
Input: Microphone
Process: Arduino Uno**
Output: LED chips
Circuit: Conductive thread***
Form: Cloth, thread, whatever else is needed
Others: Extra batteries
TO-DO LIST
Clarifications:
* How much voltage is required (what kind of battery)
** Possibility of Circuit Playground
*** How to work with thread, i.e. resistors, safety (insulation), where to find
Logistics: Procure microphone, LED chips, etc
Code: Ascertain the output, whether it be reflected in brightness level, colour hue, or lit/unlit, and write the code to receive input, analyse it, and form outputs accordingly
We decided to explore both options which we considered in class, where Elizabeth will make a post for the talking door, and I will make a post for the conversing billboard!
The original sketch.
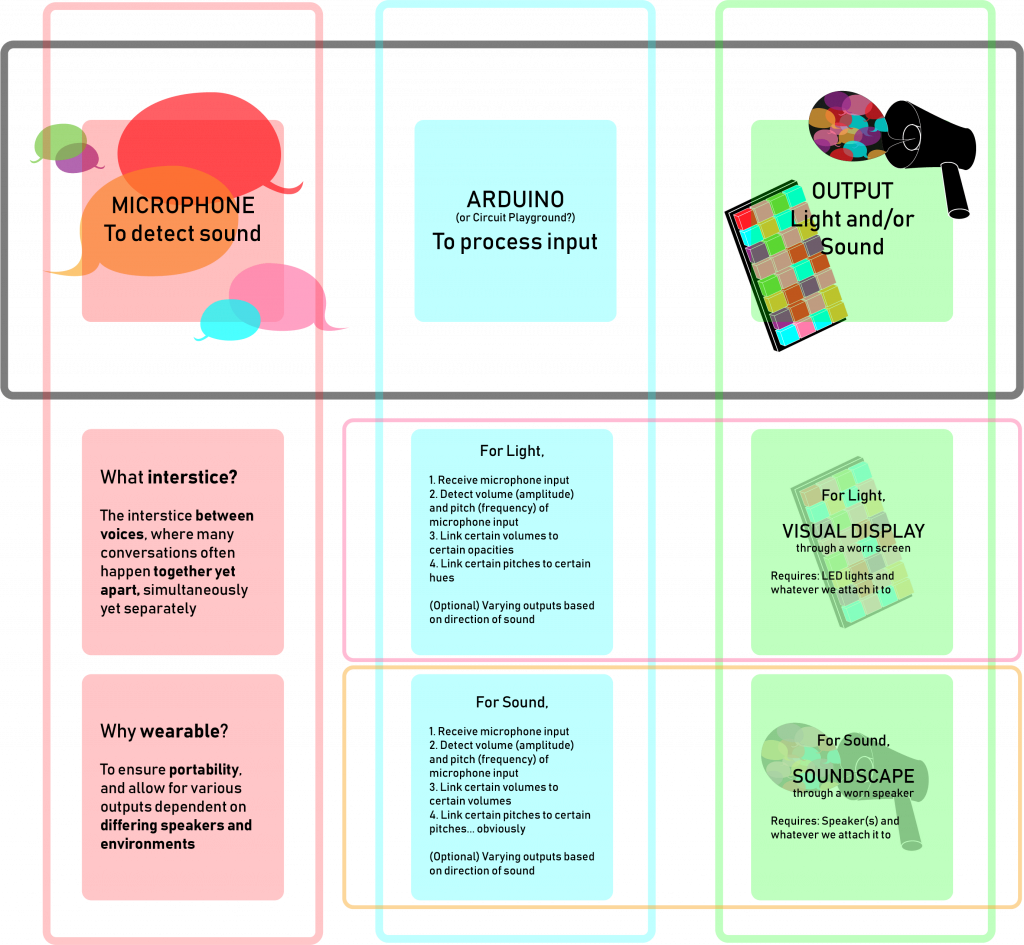
While we didn’t determine the exact output, the possibilities are mainly narrowed down to light, sound and/or text:
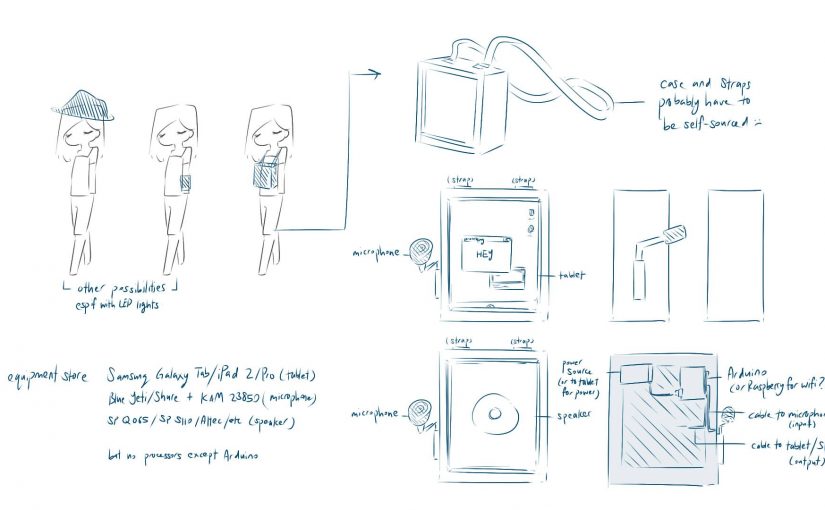
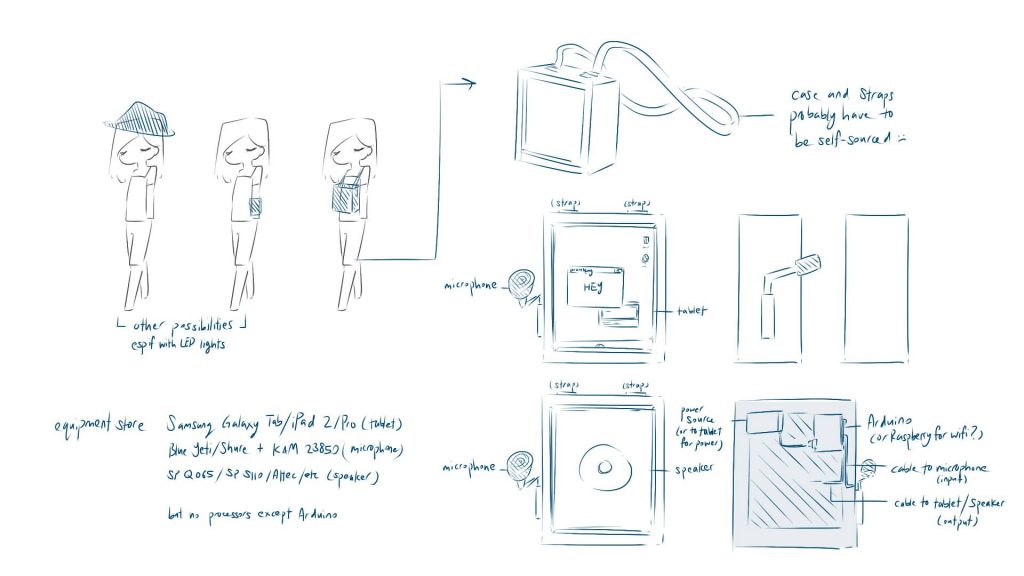
The item in mind (a carried display screen vs wearable accessory) and exact output is unconfirmed (lights, sound, or text).Example of various wearables and how it might be set up. All components needed are roughly the same, and can be hidden fairly easily due to its small size. Except for the speakers, of which one of the smallest, the Fostex Subwoofer, appears to be 13cm in height.
An even more complex possibility is of using speech-to-text code to create a direct replication than processed translation, for example:
Speech-to-text: Display various strings of text
Non-speech-to-text: Display various rgb values of light
An example of how it might work, which would be especially great in crowded places (assuming speech-to-text):
It may be possible that we will need a Raspberry Pi (for the wifi) or Circuit Playground (it’s easier for wearables).
Somebody once told me that humans are biologically engineered to instinctively look out for moving images and flashing lights. Seeing how easily we were distracted at i Light Singapore, he was probably right.
SHADES OF TEMPORALITY
Image of installation as shown on official website.
Shades of Temporality is easily one of the more interesting works presented. An homage to street art, it invites the audience to participate by painting onto the wall. The digital twist is that said paint is a video which only reveals itself when the roller detects that it is currently in the process of “painting”.
Interestingly, SWEATSHOPPE sees a much more philosophical meaning to their artwork. As the name suggests, it addresses the issue of temporality, where they are attempting to consider multiple layers of time: the experienced time of a participant’s creation of a canvas, and the edited time of a canvas moving separately from the painter.
Diagram 1: Side view of setup
Diagram 2: View of equipment (roller)
An ordered list of how it works might be like this:
Set video to play, but do not call in a command to project it
Camera tracks presence of green LED (or lack thereof)
If green LED is true,
Detect X-Y coordinates of LED positions
Store said coordinates in an array (to remember past coordinates)
Send projector the list of coordinates
Call a command to project the video at listed pixel coordinates
If green LED is false, do nothing
Somewhere, there is a button which resets the array to null whenever they switch participants
Diagram 3: Example of database system
This is a conclusion supported by both related articles and visible limitations, as evidenced by when we tried it out ourselves:
As can be seen in the video,
Lack of Z-axis detection: no matter how far from the wall, as long as the green LED is detected within the projection range, it will be registered as true. Their attempt to counter this is the button to activate it, which is affected by grip strength
Obstructions: putting the camera right behind evidently will make it impossible to write directly in front of yourself (an obstacle). In their defense, this is the best possible design, where the camera and projector must have minimal parallax error, and the roller is designed to make you subconsciously write above yourself than in front (it’s hard to wield a long item)
At 0:07, Christine and my lines intersect. I’m not sure why this happened; my only hypothesis is that there is some sort of supplementary background code which tries to account for fast movements/accidental turning off, perhaps something like this
If distance between green LED at time 1 & time 2 is small,
Assume that camera failed to track this movement, and
Fill in all coordinates in between with a linear function
Something much lower down the continuum of interactivity might be Shadow Exposed, which lacks both a feedback and database system.
SHADOW EXPOSED
Image of installation as shown on official website.
Like Shades of Temporality, Shadow Exposed is verily concerned with the nature of projection, though the focus is more on its relation with movement and light. There is an added layer of artist interest in attempting to let video “interact with the physical world”: in this case, by letting participants project their shadows against a backdrop of light and historical architecture.
Diagram 4: Side and top views
Diagram 5: With and without participation
An ordered list of how it works might be like this:
Make canvas with light-coloured materials in the shapes of architecture, which shows up better with darker backgrounds
Project video onto canvas
If projector is blocked,
Light does not shine in that area
Background is dark, thus image is clearer
Already, deviations from the sensor-based interactive artwork are evident.
My only conclusion is that the fundamental issue lay with that, while technology was involved, the interactive segment took on a fairly traditional form. If I were to make a comparison, it would be with the way a primary schooler might do shadow puppetry with a classroom projector.
While the description might lead one to believe that the video feed changes when it detects your presence, it was a constant image which varied only in terms of shadow and light, which requires no programs whatsoever as opposed to sheer physics. Is this an issue in relation to the ultimate message? Perhaps not, but it does compromise the interactivity, where this is a comparativelypassive piece.
Another issue may simply be insufficient contrast between shadow and light areas, where contents in light areas were still very clearly visible, and thus the presence of shadow didn’t “reveal” as opposed to “highlight”. For example, this sample image works well since it is truly only within the shadow that the buildings can be seen.
OTHER THOUGHTS THAT ARE NOT QUITE RELEVANT TO THE RESEARCH CRITIQUE BUT ARE HERE REGARDLESS
It is here that I wish to make a declaration, that a more precise lexicon may need to be established when speaking about interactive media. The term ‘interactive’ was used liberally to mean anything from emotional connection to talking with each other. Which isn’t necessarily wrong, but makes things rather difficult, if we wish to discuss certain types, such as sensor-based interactivity.
The question of how to identify interactive art also seems relevant here, where it is in hindsight that I realise that we had walked by this installation. (In my defense, there were many actual buoys with lights on. That is a very ordinary function of buoys. There was no reason to think otherwise.)
Then again, there is something rather endearing about a world in which interactive media has been assimilated into everyday life.
Going together with Elizabeth and Christine also led to an epiphany I might never have had otherwise: All the works were exceedingly founded on the assumption of being alone. That is not to say that it was required to only have 1 participant, of course, but that the involvement of additional participants was rarely, if ever, necessary. I find that to be a rather dismal state of affairs, considering that a majority of people would likely be coming in groups as tourists, families, colleagues… In other words, it may be worthwhile to have more interactive artworks which are founded on the assumption of companionship.