STONE – Presentation Slides PDF

















Scaling the visualisation up – “Human Stones”

Documentation Video:

Into image-making and creating spaces

Dorin, Alan, Jonathan McCabe, Jon McCormack, Gordon Monro, and Mitchell Whitelaw. “A framework for understanding generative art.” Digital Creativity 23, no. 3-4 (2012): 239-259.
Aim of the Paper
In the process of analysing and categorising generative artworks, the critical structures of traditional art do not seem to be applicable to “process based works”. The authors of the paper devised a new framework to deconstruct and classify generative systems by their components and their characteristics. By breaking down the generative processes into defining components – ‘entities (initialisation, termination)’, ‘processes’, ‘environmental interaction’ and ‘sensory outcomes’ – we are able to critically characterise and compare generative artworks which underlying generative processes, as compared to outcomes, hold points of similarity.
The paper first looked at different attempts at and previous approaches of classifying generative art. By highlighting the ‘process taxonomies’ of different disciplines which adopt the “perspective of processes”, the authors used a ‘reductive approach’ to direct their own framework for the field of generative art in particular. Generative perspectives and paradigms began to emerge in the various seemingly unrelated disciplines, such as biology, kinetic art and time-based arts and computer science, adopting algorithmic processes or parametric strategies to generate actions or outcomes. Previous studies explored specific criterions of emerging generative systems by “employing a hierarchy, … simultaneously facilitate high-level and low-level descriptions, thereby allowing for recognition of abstract similarities and differentiation between a variety of specific patterns” (p. 6, para.4). In developing the critical framework for generative art, the authors took into consideration of the “natural ontology” of the work, selecting a level of description that is appropriate for the nature. Adopting “natural language descriptions and definitions”, the framework aims to serve as a way to systematically organise and describe a range of creative works based on their generativity.
Characteristics of ‘Generative Art System’
Generative art systems can be broken down into four
(seemingly) chronological components – Entities, Processes, Environmental Interaction and Sensory Outcomes. As generative art are not characterised by the mediums of their outcomes, the structures of comparison lie in the approach and construction of the system.
All generative systems contain independent actors ‘Entities’ whose behaviour is mostly dependent on the mechanism of change ‘Processes’ designed by the artist. The behaviours of the entities, in digital or physical forms, may be autonomous to a certain extent decided by the artist and determined by their own properties. For example, Sandbox (2009) by artist couple Erwin Driessens and Maria Verstappen, is a diorama of a terrain of sand is continuously manipulating by a software system that controls the wind. The paper highlight how each grain of sand can be considered the primary entities in this generative system and how the system behaves as a whole is dependent on the physical properties of the material itself. The choice of entity would have an effect on the system, such as in this particular work where the properties of sand (position, velocity, mass and friction) would have an effect on the behaviour of the system. I think the nature of the chosen entities of a system is important factor, especially when it comes to generative artworks that use physical materials.
The entities and algorithms of change upon them also exist within a “wider environment from which they may draw information or input upon which to act” (p. 10, para. 3). The information flow between the generation processes and their operating environment can be classified as ‘Environmental Interaction’, where incoming information from external factors (human interaction or artist manipulation) can set or change the parameters during execution which leads to different sets of outcomes. These interactions can be characterised by “their frequency (how often they occur), range (the range of possible interactions or amount of information conveyed) and significance (the impact of the information acquired from the interaction of the generative system)”. The framework also classifies interactions as “higher-order” when it involves the artist or designer in the work, where he can manipulate the results of the system through the intermediate generative process or adjusting the parameters or the system itself in real-time, “based on ongoing observation and evaluation of its outputs”. The higher order interactions are made based on feedback of the generated results, which hold similarities to machine learning techniques or self-informing systems. This process results in changes to its entities, interactions and outcomes and can be characterised as “filtering”. This high order interaction is prevalent in the activity of live-coding, relevant to audio generation softwares which supports live coding such as SuperCollider, Sonic Pi, etc, where performance/ outcome tweaking is the main creative input.
The last component of generative art systems is the ‘Sensory outcomes’ and they can be evaluated based on “their relationship to perception, process and entities.” The generated outcomes could be perceived sensorially or interpreted cognitively as they are produced in different static or time-based forms (visual, sonic, musical, literary, sculptural etc). When the outcomes seems unclassifiable, they can be made sense of through a process of mapping where the artist decides on how the entities and processes of the system can be transformed into “perceptible outcomes”. “A natural mapping is one where the structure of entities, process and outcome are closely aligned.”
Case studies of generative artworks
The Great Learning, Paragraph 7 – Cornelius Cardew (1971)
Paragraph 7 is a self-organising choral work performed using a written “score” of instructions. The “agent-based, distributed model of self-organisation” produces musically varying outcomes within the same recognisable system, while it is dependent on human entities and there is room for interpretation/ error in the instructions, similarities with Reynolds’ flocking system can be observed.
Tree Drawings – Tim Knowles (2005)
Using natural phenomena and materials of ‘nature’, the movement of wind-blown branches to create drawings on canvas. The found process of natural wind to be used as the generator of movement of the entities highlights the point of the effect of physical properties of chosen materials and of the environment. “The resilience of the timber, the weight and other physical properties of the branch have significant effect on the drawings produced. Different species of tree produce visually discernible drawings.”
The element of surprise is included in the work, where the system is highly autonomous, where the artist involvement includes the choice of location and trees as well as the duration. It brings to mind the concept of “agency” in art, is agency still relevant in producing outcomes in generative art systems? Or is there a shift in the role of the artist when it comes to generative art?


The Framework on my Generative Artwork ‘SOUNDS OF STONE’

Visual system:
Work Details
‘Sounds of Stone’ (2020) – Generative visual and audio system
Entities
Visual: Stones, Points
Audio: Stones, Data-points, Virtual synthesizers
Initialisation// Termination:
Initialisation and termination determined by human interaction (by placing and removing a stone within the boundary of the system)
Processes
Visual and sound states change through placement and movement of stones
Each ‘stone’ entity performs a sound, where each sound corresponds to its visual texture (Artist-defined process)
Combination of outcomes depending on the number of entities is in the system
“Live” where artist or performer or audience can manipulate the outcome after listening/ observing the generated sound and visuals.
Environmental Interaction
Room acoustics
Human interaction, behaviours of the participants
Lighting
Sensory Outcomes
Real-time/ live generation of sound and visuals
Audience-defined mapping
As the work is still in progress, I cannot evaluate the sensory outcomes of the work at this point. According to the classic features of generative systems used to evaluate Paragraph 7 (performative instructional piece) such as “emergent phenomena, self-organisation, attractor states and stochastic variation in their performances”, I predict that the sound compositions of “Sound of Stones” will go from being self-organised to chaotic as the participants spend more time within the system. Existing as a generative tool or instrumental system, I predict that there will be time-based familiarity with the audio generation with audience interaction. With ‘higher order’ interactions, the audience will intuitively be able to generate ‘musical’ outcomes, converting noise into perceptible rhythms and combinations of sounds.
Using the sound generation system I used in my generative sketch:
RECAP for Generative Artwork:
Aiming to extract a sound from the visual textures of stone involves two aspects:
1. Subtracting three-dimensional forms of the material into visual data that can be converted into audio/ sounds
2. Designing a model that generates sounds that the audience would perceive/ associate the tactile qualities of the specific material.
POSSIBLE APPROACH
DIRECTION

CONCEPT
How do materials sound like? While sound is subjectively perceived, there is a collective or general sentiment on the descriptive qualities of a sound/ soundscape. We occasionally use tactile qualities (eg. rough, soft) to describe sounds, to assign textures to what we hear. In music, texture is the way the tempo, melodic and harmonic materials are combined in a composition, thus determining the overall quality of the sound in a piece. However, most sounds that we hear are more complex than simple harmonies, there is a more complicated process behind how we can perceive and cognitively recognised textures in sound. My project explores how visual textures of physical materials (stones) can be translated to the auditory, creating an interactive system to draw out the direct link between sound and textures.
CASE STUDY – Classification of Sound Textures
Saint-Arnaud, N. (1995). Classification of sound textures (Doctoral dissertation, Massachusetts Institute of Technology).
http://alumni.media.mit.edu/~nsa/SoundTextures/
“The sound of rain, or crowds, or even copy machines all have a distinct temporal pattern which is best described as a sound texture.” (Saint-Arnaud, 1995). Sounds with such constant long term characteristics are classified as Sound Textures. The thesis investigates the aspects of the human perception and machine processing of sound textures.
“Between 1993 and 1995, I studied sound textures at the MIT Media Lab. First I explored sound textures from a human perception point of view, performing similarity and grouping experiments, and looking at the features used by subjects to compare sound textures.
Second, from a machine point of view, I developed a restricted model of sound textures as two-level phenomena: simple sound elements called atoms form the low level, and the distribution and arrangement of atoms form the high level. After extracting the sound atoms from a texture, my system used a cluster-based probability model to characterize the high level of sound textures. The model is then used to classify and resynthesize textures. Finally, I draw parallels with the perceptual features of sound textures explored earlier, and with visual textures.”
His approach to sound textures from both the perspectives of subjective human perception and technical synthesis and processing of sound textures is especially relevant to my project. The difference is that the thesis explores the perceptual and machine constructs of existing sound textures, while I am trying to generate sounds that could be perceived/ associated with the actual tactile qualities of a material. I could say that my process (associating texture to sound) works in the opposite direction from his (associating sound to texture).
Aiming to extract a sound from the visual textures of stone involves two aspects:
1. Subtracting three-dimensional forms of the material into visual data that can be converted into audio/ sounds
2. Designing a model that generates sounds that the audience would perceive/ associate the tactile qualities of the specific material.
PROCESS
While his project is conducted on a large scale with the abundance of time and resources (MIT lab), it was conducted a while back (1993-1995). With the introduction of many audio-generation software and sound visualisation/ analysis technologies, my project might be feasible in the short span of time that we have (6 more weeks to Week 13).
Visual textures to Sound – WaveTable Synthesis
I previously explored wavetable synthesis on SuperCollider (one wavetable to another), but I was not able to visualise a combined three-dimensional model of the periodic waveforms with the sound produced (only singular wave forms). For me to design a model for sound textures, I would need to be able to connect the sound I hear to 3D wavetable. I would have to experiment more with sound synthesis to decide on the type and range of sounds I would like to generate. Based on the above paper, I would look at perceptual features of sound textures to formulate how I could associate a tactile quality/ mood to what we hear.
Ableton Live 10: Sound Design with Wavetable
Obtaining visual data/ 2D forms from 3D material – 3D scanning and processing
To be able to generate data in real-time based on the stone used and its movement, I would need a software to process the captured data (RGB data/ 3D scanning) by the kinect/ camera.
Possible software: 3D Scanner Windows 10 App, OnScale, CocaoKinect


I would have to obtain the 2D line vectors/ waves from a 3D scan and use them to compose a 3D wavetable to be played ideally in real-time.

Connecting Both – Open Sound Control (OSC)
I have previously worked with OSC to connect processing to SuperCollider, I will continue working on it. I would also like to find a way to design a more complex soundscape on SuperCollider by either inputting the designed wavetable synthesis or individually manipulating the way the sound is played for each sound (pitch, amp, freq, etc).
If the wavetable does not work out:
I would then use data values instead of visualised lines. Referencing Aire by Interspecifics, I would assign individual data line/points in a 3D space to specific designed synthesizers programmed on SuperCollider. Depending on the 3D forms thus there would be varying depth values on the data line, different sounds would be produced and played in consonance/ dissonance.
I would still have to study the soundscape design of Aire on their github to learn more about sound design and layering: https://github.com/interspecifics/Aire
SURPRISE
The concept of surprise is explored in my project through the dissonance between our perceptive modalities, where we usually generalise that they are mutually exclusive when we know they are not. Connecting the links between what we see, hear and touch, I am trying to touch upon the unnoticed relationships between our senses and try to play around with how our minds cognitively make sense of the world.
With sound as an intangible material, we don’t usually connect what we physically see to what we hear. When an instrument is played (eg. a key is pressed, a string is struck), the act serves as a trigger but it is not the only component to the sound we hear. Being human, we can’t fully understand how a sound is visually and technically synthesised beyond what we hear. With technology, we are able to work with the other end of the spectrum of generating sound (where we work from the visual/ components of sound).
Working with textures, I want to associate tactile quality to sound to enhance the experience with a material and its materiality. Stones are intriguing in themselves, even though seemingly fixed, their forms are intrinsically beautiful. Connecting their visual textures to sound seems like a way to explore their spirit.
TIMELINE
Week 9-10: Work on Sound/ wavetable synthesis + Obtaining visual data
Week 11-12: Design soundscape and interaction with stones
Week 13: Set-up

SOUND OF STONES
Generative Study:
Real-time sound generation using depth data from kinect
Over Week 7, I experimented with SuperCollider, a platform for real-time audio synthesis and algorithmic composition, which supports live coding, visualisation, external connections to software/hardware, etc. On the real-time audio server, I wanted to experiment with unit generators (UGens) for sound analysis, synthesis and processing to study the components of sound through the programming language and visually (Wavetable). The physical modelling functions (plot, frequency analyser, stethoscope, s.meter, etc) would allow me to explore the visual components of sound.
Goals
Initially, I was going to work with Python to generate data flow into SuperCollider but Processing would be more suitable for smaller sets of data.
SuperCollider
SynthDef() is an object which allows us to create a function (design of a sound), and the sound generation has to been run using the Synth.new() or .play line eg. x = Synth.new(\pulseTest);. This allows us to create different types of sound in the SynthDef(/name) function and the server allows us to play and combine the different sounds live (live-coding).
Interesting functions:
Within SuperCollider, there are interesting variables that can be used to generate sound other than the .play function. This would be relevant to my project where I would like to generate the sounds or the design of the sound using external data from the kinect. The functions I worked with include MouseX/Y (where the sound varies based on the position of the mouse), Wavetable synthesis and Wave Shaper (where the input signals are shaped using wave functions) and Open Sound Control (OSCFunc which allows SuperCollider to receive data from external NetAddr.).
MouseX
Multi-Wave Shaper (Wavetable Synthesis)
SuperCollider Tutorials (really amazing ones) by Eli Fieldsteel
Link: https://youtu.be/yRzsOOiJ_p4
https://funprogramming.org/138-Processing-talks-to-SuperCollider-via-OSC.html
Processing + SuperCollider
My previous experimentation involves obtaining depth data (x, y, z/b) from the kinect and processing the data into three-dimensional greyscale visuals on Processing. The depth value z is used to generate a brightness value, b, from white to black (0 to 255) which is reflected in each square of every 20 pixels (skip value). To experiment with using real-time data to generate sound, I thought the brightness data, b, generated in the processing sketch would make a good data point.
Connecting Processing to SuperCollider
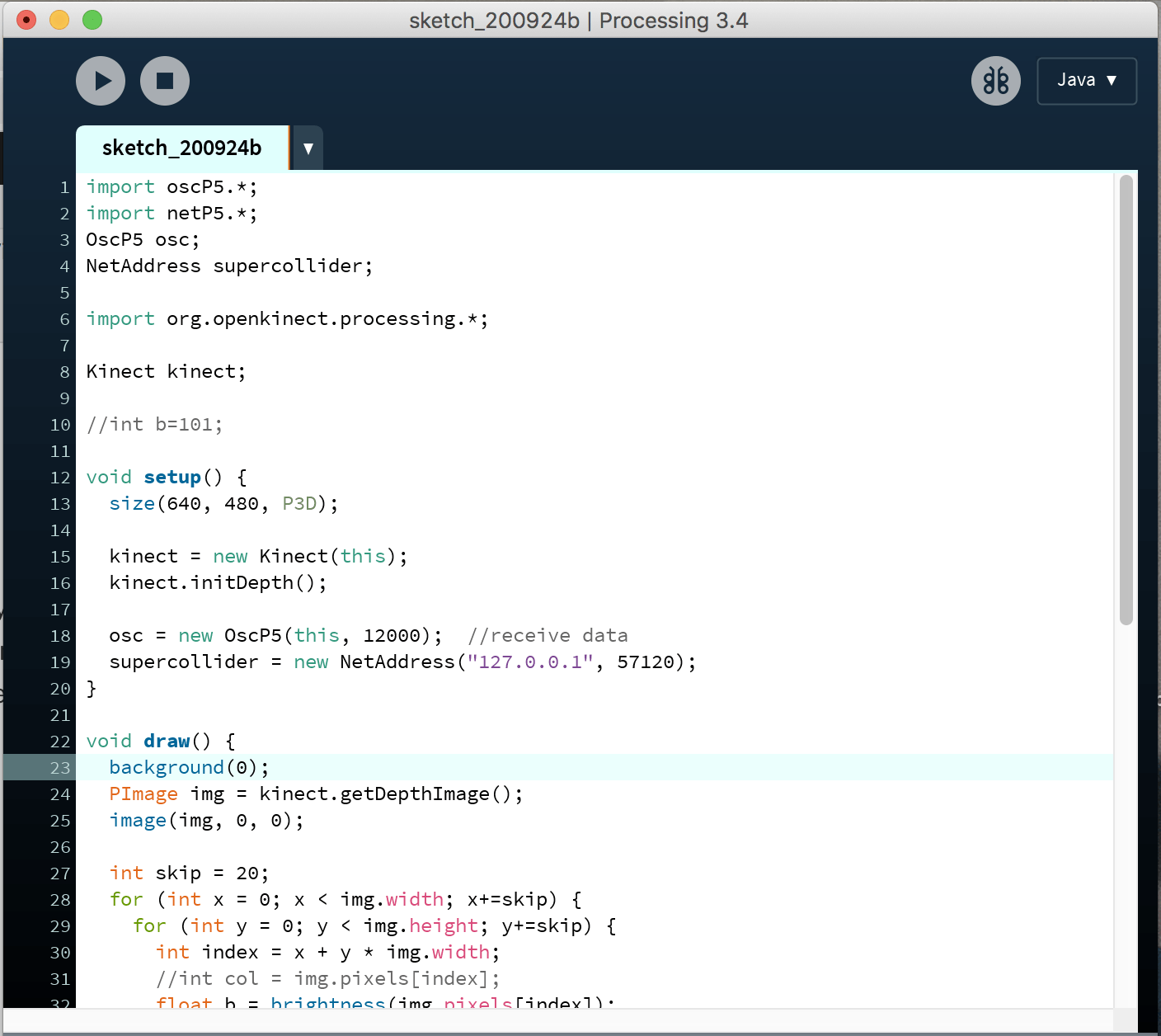
Using the OscP5 library in Processing, we input data into a NetAdress that will be redirected into SuperCollider.
Using the brightness value, when the b value is more than 100, a message ‘/brightness’ is sent to OSC SuperCollider.


When the OSCdef() function is running in SuperCollider, and you receive ‘-> OSCdef(brightness, /brightness, nil, nil, nil)’ in the Post window, it means that it is open to receiving data from Processing. After running the processing sketch, whenever the message ‘/brightness’ is received, the Synth(‘stone1’) will be played.
Generative Sketch – Connecting depth data with sound
For the purpose of the generative sketch, I am working with using data as a trigger for the sound that has been pre-determined in the SynthDef function. Different SynthDef functions can be coded for different sounds. So far, the interaction between kinect and the sound generation is time-based, where movement generates the beats of a single sound. For larger range of sounds specific to the captured visual data, and thus textures, I would have to consider using the received data values within the design of each sound synthesizer.
Improvements
I see the generative sketch as a means to the end, so by no means does it serve as a final iteration. It was a good experiment for me to explore the SuperCollider platform which is new to me, and I was able to understand the workings of audio a little better. I would have to work more on the specifics of the sound design, playing with its component, making it more specific to the material.
Further direction and Application
Further experiments would be to use more data values (x, y, z/b) beyond the sound generation (Synth();) but be used in the design of the sound (Synthdef();). A possible development is to use Wave Shaper function to generate sounds specific to the Wavetable generated using functions that are manipulated or transformed using the real-time data from kinect.

Generative Sound and Soundscape Design
I would like to use the pure depth data of three-dimensional forms to map the individual soundscape (synthesizer) of each sound, so that the sound generated would be specific to the material. This relates to my concept of translating the materiality into a sound, where the textures of the stone correspond to a certain sound. So, if the stone is unmoved under the camera, an unchanging loop of a specific sound will be generated. When different stones are placed under the camera, the sounds would be layered to create a composition.
In terms of instrumentation and interaction, I can also use time-based data (motion, distance, etc) to change different aspects of sound (frequency, amplitude, rhythm, etc). The soundscape would then change when the stones are moved.
Steps for Generative Study:
I have yet to establish a threshold on the kinect to isolate smaller objects and get more data specific to the visual textures of materials. I might have to explore more 3D scanning programs that would allow me to extract information specific to three-dimensionality.
My next step would be to connect more data points from processing to Supercollider and try to create more specific arguments in SynthDef(). After which, I would connect my Pointcloud sketch to Supercollider where I might be able create more detailed sound generation specific to 3D space.
Link to Performance and Interaction:
Proposal for Performance and Interaction class:
https://drive.google.com/file/d/1U5J0XajPlCrGfuhPQEI6J1zQDqRu2tJL/view?usp=sharing

Audio Set up for Mac (SuperCollider):
Audio MIDI Setup
Amplifying The Uncanny
Analysing the methodology and applications of Machine Learning and Generative Adversarial Networks (GAN) framework.
Computational tools and techniques, such as machine learning and GAN, are definitive to the applications of such technology for a generative purpose. The paper explores the exploitations of these deep generative models in the production of artificial images of human faces (deepfakes) and in turn invert its “objective function” and turn the process of creating human likeness to that of human unlikeness. The author highlighted the concept of “The Uncanny Valley”, introduced by roboticist and researcher Masahiro Mori, which theorises the dip in feelings of familiarity or comfort when increasing human likeness of artificial forms reaches a certain point. Using the idea of “the uncanny”, Being foiled maximises human unlikelihood by programming the optimisation towards producing images based on what the machine predicts are fake.
Methodology
Machine Learning uses the process of optimisation (the best outcome) to solve a pre-defined objective function. The algorithms used to process data produce parameters that categorise what can be generated (by the choice of function). In producing deepfakes through the GAN framework, the generator serve to produce random samples and the discriminator is optimised to classify real data as being real and generated data as being fake, where the generator is trained to fool the discriminator.
Being foiled uses the parameters generated by the discriminator which predicts signs that the image is fake to change the highly realistic samples produced by the generator. It reverses the process of generating likelihood to pin-point at which point do we cognitively recognise a human face to be unreal, which relates to a visceral feeling of dissonance (the uncanny valley). When the system generates abstraction, where images cannot be cognitively recognised, I would imagine that the feelings of discomfort dissipates. In a way, Being Foiled studies the “unexplainable” phenomena of human understanding and feelings.
Applications
As a study, I feel that the generative piece serves its purpose of introspective visual representations of uncanniness. However, the work should exist as more than “aesthetic outcomes” and the learning can be applied to various fields, such as AI and human robotics, that develop and explore human likeness and machines.
The Artificial Intelligence field is quite advanced in the development of intelligent technology and computers that mimic human behaviour and thinking, threading the fine line of what is living and what is machine. Considering the analogue forms of art, Hyperrealism saw artists and sculptors, such as Duane Hanson and Ron Mueck, recreating human forms in such detail that it is hard to differentiate which is real and unreal visually. When it comes to robotics and artificial intelligence, what defines it to be “human” is the responses that are produced by the human mind and body. By studying the data collected on “normal” human behaviour, the AI systems generate responses trained to be human-like. “The Uncanny Valley” explores the threshold of human tolerance for non-human forms, where imitation no longer feels like imitation, which is often referenced in the field. With Being Foiled, the point where uncanniness starts to develop visually can be tracked and the information can be used when developing these non-human forms.

Where “Being Foiled” can be applied
When I was in KTH in Stockholm, I was introduced and had the experience of using and interacting with an artifical intelligence robot developed by the university. Furhat (https://furhatrobotics.com/) is a “social robot with human-like expressions and advanced conversational artificial intelligence (AI) capabilities.” He/ She is able to communicate with us humans as we do with each other – by speaking, listening, showing emotions and maintaining eye contact. The computer interfaces combines a three-dimensional screen to project human-like faces, which can be swapped according to the robot’s identity and intended function. Furhat constantly monitors the faces (their position and expressions) of people in front of it, making it responsive to the environment or the people it is talking to.
Article on Furhat:
https://newatlas.com/furhat-robotics-social-communication-robot/57118/
“The system seems to avoid slipping into uncanny valley territory by not trying to explicitly resemble the physical texture of a human face. Instead, it can offer an interesting simulacrum of a face that interacts in real-time with humans. This offers an interesting middle-ground between alien robot faces and clunky attempts to resemble human heads using latex and mechanical servos.”
When interacting with the Furhat humanoid, personally I did not experience any feelings of discomfort and it seemed to have escape the phenomenon of “the uncanny valley”. It even seemed friendly and have a personality.
It is interesting to think that a machine could have a “personality” and the concept of ‘the uncanny valley’ was brought up when I was learning about the system. What came to my mind was at which point of likeness to human intelligence would the system reach the uncanny valley (discomfort) beyond just our response to the visuals of human likeness. Can we use the machine learning technique that predicts what is fake or what is real on images (facial expressions) for actual human behaviours (which is connected to facial behaviour in the Furhat system)? -> how I would apply the algorithm/ technique explored in the paper
An interesting idea:
Projecting the “distorted” faces on the humanoid to explore the feelings of dissonance when interacting with the AI system

Conclusion
While generative art cleverly makes use of machine learning techniques to generate outcomes that serve objective functions, the produced outcomes are very introspective in nature. The outcomes should go beyond the aesthetic, where the concept can be applied in very interesting ways with artificial intelligence and what it means to be human.
SOUND OF STONES
Project: Creating an instrumental system that uses visual data of textures (stones) to generate sound in real time
For the project, there are two parts:
1. Converting three-dimensional forms into visual data
2. Connecting the data with audio for real-time generation
Generative Sketch
Over week 5, I experimented with the depth image and raw depth data from kinect to processing to see what kind of visual data (colour/brightness, depth, etc) can be obtained from a camera. The kinect has three key components, infrared projector, infrared camera and RGB camera, from which the captured three-dimensional visual data can be sent to processing.
Using ‘depth image’
With the ‘depth image’ sketch, the data values, x (horizontal position) and y (vertical position) of the pixel from the kinect are mapped on recorded image. The sketch involves looking at each pixel (x, y), looking at the index of the depth image and obtaining the colour/ brightness (b – single value between 0 and 255). A rectangle of a fixed size is mapped using z value (depth in 3D space) according to their brightness value b, where things that are dark to appear close and things that are bright to be farther away.
The purpose of this sketch is to see what data values can be obtained from the kinect and see if I use the data as input for audio generation. From this sketch, the depth data from a kinect that can be obtained are x, y, z, b values, that I think can be used to as input data to map textures of three-dimensional forms.
Using ‘Raw depth data’ to map forms on a point cloud
For scanning three dimensional forms, raw depth data (kinect1: 0 to 2048 and kinect2: 0 to 4500) from the kinect might be more useful to generate information about textural surfaces in 3D space. The point cloud can be used to map all the points the kinect is obtaining in a 3D space (from the infrared projector).
By giving each pixel an offset value (= x + y * kinect.width), we get a raw depth value d (= depth[offset]). Each PVector point (x, y, d) on the point cloud can be pushed into the three dimensional plane to map the object the kinect is seeing. For smaller objects (I have yet to try this out), a minimum and maximum depth threshold can be used to look only a particular set of pixels, to isolate an object that is close to the kinect.
Tutorial sources:
https://www.youtube.com/watch?v=FBmxc4EyVjs
https://www.youtube.com/watch?v=E1eIg54clGo
For sound generation
Initially, I looked into virtual modular synthesizer program (VCV Rack) to generate the sounds and if they could be coded in real time. However, the programme exists only as a modular synthesizer, a good one, to develop complex audio.
I am interested in sending real-time data from the kinect/ camera/ sensor into an audio-generating software. Referencing Aire CDMX (2016) by Interspecifics, I found out that I could use Python (data access) and SuperCollider (virtual synthesizers) to connect data flow to sounds that I design.
Aire CDMX (2016) by Interspecifics
http://interspecifics.cc/wocon
https://muac.unam.mx/exposicion/aire?lang=en
Aire is a generative sound piece that uses data that environmental sensors pick up in real-time in Mexico City. Using a software written in Python to access the real-time data of pollutants, the data flow is used to animate an assembly set of virtual synthesizers programmed in Supercollider. “In the piece, each one of the pollutants has its own sound identity and the fluctuation of the information modulates all its characteristics.”
From this work, I can study their code as a reference to find a way to map data to designed sounds on Supercollider. As it is my first time working with Python, I might need some help writing the code that specifically works for my project.
Source Code: https://github.com/interspecifics/Aire
For Week 7 Generative Sketch
For the next two weeks, I will be working on connecting the raw data values from the kinect to virtual synthesizers that I will develop on SuperCollider. My aim is to see what sounds can be generated when a three-dimensional object is captured using a kinect.
Direction for Week 7:
1. Connecting kinect data to Python
Some references: on Linux with pylibfreenect2 https://stackoverflow.com/questions/41241236/vectorizing-the-kinect-real-world-coordinate-processing-algorithm-for-speed
2. Experiment with SuperCollider to create virtual synthesizers
3. Connect Python and SuperCollider to generate sound using data flow
For Final Project Generative Study
For the final project, my goal is to map visual textures of materials, in particularly stones, to generate an auditory perception to the material. Rather than using raw depth data, I would like to obtain more data specific to three-dimensional forms.
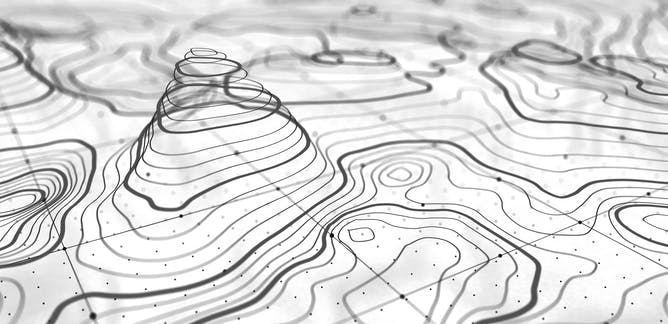
Ideation – Using Topography data
https://arsandbox.ucdavis.edu/#sidr
Topography, in geography, is the study of the arrangement of the natural and artificial physical features of an area. When looking at topographic sketches, I wonder if it can be scaled down to map three-dimensional forms by the circumferences formed by intersecting horizontal planes. I would have to research into 3D scanning software and the type of data that can be obtained. How I imagine it would be convert each layer of visual shapes into a corresponding audio feedback (maybe in terms of how the sound wave is shaped/developed).

AR Sandbox by UC Davis
The AR Sandbox is an interactive tool combined with 3D visualisation applications to create real-time generation of an elevation color map, topographic contour lines and simulated water when the sand is augmented. I think that the 3D software used to track the changes in forms can be applied to my project, where the contour lines generated by the stones can serve as data or input for sound. I would have to research more into this after I complete the experimentation for the generative study.
I would consider using the sensors that were suggested (RGB+ Clear and IR (facture)) to use for capturing data. I would first work with the kinect, but if the data generated is insufficient or not specific, I would consider other options. I would have to think about where to position the kinect and also use the threshold from the kinect raw depth data tutorial to isolate the captured object.
Other References:
To study texture:
Vija Celmins – photo-realistic nature
Concept development for interaction
Just a possibility:
If the code for capturing real-time visual data is developed enough, I would have the participants collect stones from a walk/ on their path to create generative pieces specific to a journey.
Or it could just exist as a instrumental tool to play around with the sound textures.
Connecting to Performance and Interaction:
I would like to use the developed system on a bigger scale for a performance piece for the semester project for Performance and Interaction class. It would involve capturing human-sized objects in a space on a bigger scale, which would change the threshold of the captured space.
CONCEPT – Converting texture of three-dimensional forms into sound
My idea is to create a ‘instrumental’ system to generate sound using data from physical materials. To me, instruments are generative systems, while composed music are outcomes. Intrigued by our material perception, I would like to map the patterns of stones (primary medium of interest) and convert the visual data into sound waves/ audio signals in real-time. I am interested in exploring the perceptual commonalities of our senses of sight, touch and hearing. When we touch a ‘rough’ material and we hear a ‘rough’ sound, how do we cognitively recognise or associate a tactile quality of ‘roughness’ to what we sense? My project is an attempt to connect material textures (through sight and touch) to sound textures.
Perimeters/ Structure of system:
Connecting textural qualities (visual) to auditory qualities, the sound quality will vary according to the type of stone/ texture used. I would define a space when the stones can be placed in the range of the camera lens (kinect). When the stone is stationary, the three dimensional data captured by the camera will be mapped as two-dimensional lines to be converted into sound waves (Need for a software that connects visual data to audio). I will also experiment with other forms of data (numerical based on volume/ texture density) that can be converted into audio data.
“Oh that sounds like a rough rock!” “That sounds like a smooth stone!”
Interaction design:
Each stone when placed under camera will have a sound loop related to their material qualities. The audience can move the stone to change the sound, using movement feedback as a ‘synthesizer’. Stones of different textures can be switched and combined, to ‘play’ the instrument to generate music in real time.
Inspirations
TECHNICAL EXPLORATIONS
– Kinect and processing/ Touchdesigner
– VCV Rack (software modular synthesizer)
– Research into visual-feedback audio software
A system, composed of parts working together as a whole, is our way of understanding structures and phenomena in the world. One of the reasons why we are so in awe by nature alludes to the power of creation, subjective to the limitations of the human hands. Nature “evolved from the harmony of the myriad of chances and necessity” and is a constellation of systems that generate forms and phenomena. It is in human culture to break down phenomena into systems, for example, formulating scientific principles to explain how the material world works.
We can take inspiration from the organic “processes found in nature” to condition unpredictability into systems that can generate outcomes infinitely. Generative systems are mechanisms used to create structures that “could not be made by human hands”, using computational models that combine encoded “organic behaviour and spontaneous irregularities” with logic. These systems come in the form of computer language and digital tools, which are malleable in nature. One small change in the code/ algorithm can lead to a variety of outcomes, or different combinations of written code/ conditional factors can be used to achieve the same or similar outcomes.
The process of using computational systems to generate aesthetic processes involves translating individual components into a series of decisions that can serve as building blocks for the desired result. These decisions have to be interpreted as computer code to satisfy each functional element of the system and the programming process involves a lot of reverse-engineering and ‘trial and error’ to work around the tendencies of the computer algorithms used. The art of coding is the clever manipulation of these generative systems – “choosing computational strategies and appropriate parameters in a combination of technical skill and aesthetic intuition.”
It is interesting to think of Generative Art as works categorised by the strategy of adopting a “certain methodology”, as compared to art movements which are paradigms of works defined by the characteristics or ideology. The aesthetic application of rules and systems is key in generative art works, where the artist designs a closed system by setting conditions and perimeters, in which the unpredictable outcomes exist. Not all generative art has to be code-based, but the art is in the system instead of the results. This allows the work to be timeless, where as long as the conditions of the system are available, the outcomes can be generated infinitely.
The next step for Generative Art:
Watz states that while computer code algorithms are essentially immaterial, they display material properties. It would be interesting to see the material properties translated into sensory ones, where computer code algorithms can be used to generate sensory experiences. Sensory perception is specific to the person, and what one perceive would a subjective experience of the generated sensory activation, which can be seen as a form of unpredictability and generativity.
INTERSPECIFICS
INTERSPECIFICS is an artist collective from Mexico City (founded 2013), experimenting in the intersection between art and science (Bio-Art/ Bio-Technology). Their creative practice revolves around a collection of experimental research and methodological tools they named “Ontological Machines”, which involve exploring the communication pathways between non-human actors and developed systems, such as machines, algorithms and bio-organisms. Their body of work focuses on the use of sound and AI to deconstruct bioelectrical data and chemical signals of various living organisms as generative instruments for inter-species communication, pushing our understanding of the boundaries of human nature and its counterpart, the non-human.

ONTOLOGICAL MACHINES
An exhibition presented by INTERSPECIFICS of two installation-based sets of hardware they define as ‘ontological machines’. The methodological classification serves as a framework to explore the complex expressions of reality, where the systems/ mechanisms exists as communication tools which breaks down the patterns of bio-mechanisms using electromagnetic signals and artificial intelligence.

Micro-Rhythms, 2016
“Micro-rhythms is a bio-driven installation where small variations in voltage inside microbial cells generate combining arrays of light patterns. A pattern recognition algorithm detects matching sequences and turns them in to sound. The algorithm written in Python uses three Raspberry Pi cameras with Open Computer Vision to track light changes creating a real-time graphic score for an octophonic audio system to be played with SuperCollider. The cells are fuelled using soil samples from every place where the piece is presented, growing harmless bacteria that clean their environment and produce the micro signal that detonates all the processes in the piece. Understood as an interspecies system, the installation amplifies the microvoltage produced by these microscopic organisms and transduces their oscillations into pure electronic signals with which they create an audiovisual system that evokes the origins of coded languages.”



Speculative Communications, 2017


“A machine that can observe and learn from a microorganism and uses the data arising from its behavioural patterns as a source of composition for an audiovisual score. This project is focused on the creation of an artificial intelligence that has the ability to identify repeated coordinated actions inside biological cultures. The AI stores and transforms these actions in to events to which it assigns different musical and visual gestures creating an auto-generative composition according to the decision making logic it produces through time. To accomplish this we will development an analog signal collector and transmission device able to perform its own biological maintenance and an audiovisual platform allowing the expression of these biological signals. The resulting composition will be transmitted live via a server channel where the coevolution process can be monitored in real time. Inspired by research centres such as SETI (Search for extraterrestrial intelligence), Speculative Communications is part a research space for non anthropocentric communication and part a non-human intelligence auto-generative system.”


The artistic approach of generating communications through audio-visual means between non-human organisms is novel to me. The gathering and processing of data using machine learning algorithms and artificial intelligence and the real-time generation of light and sound through the signals serves as a new way for us to understand these forms. The choice of output may be biased to us as humans but do these non-human forms see a need to communicate? Nevertheless, I think INTERSPECIFICS’ paradigm of work is experimental and innovative, the methodological approach focused on their point of interest in Bio-technology (bacteria, plants, slime molds) and creating a communicative link between humans and non-humans through ‘machines’ – a culmination of scientific knowledge and computer systems.